Google представила TurboQuant: алгоритм, который в шесть раз снижает потребление памяти ИИ без ущерба для качества
Исследователи Google Research 24 марта 2026 года объявили о новом прорыве в области сжатия данных для искусственного интеллекта. Алгоритм TurboQuant, разработанный командой под руководством Амира Зандиха и Вахаба Миррокни, предлагает радикальное решение одной из самых острых проблем современных больших языковых моделей - огромного объёма рабочей памяти, необходимой для обработки длинных контекстов. Вместо того чтобы просто уменьшать модель,
TurboQuant фокусируется на ключевом узком месте - кэше ключей и значений (KV-cache) в механизмах внимания трансформеров, сжимая его минимум в шесть раз без какой-либо потери точности.
Проблема KV-cache хорошо знакома всем, кто работает с ИИ. Во время генерации текста модель сохраняет промежуточные результаты внимания, чтобы не пересчитывать их заново на каждом шаге. При росте окна контекста до сотен тысяч токенов этот кэш разрастается экспоненциально и быстро становится самым дорогим ресурсом - как по памяти, так и по скорости.
Традиционные методы квантизации (снижения разрядности) помогали, но вводили дополнительные накладные расходы: для каждого маленького блока данных приходилось хранить константы квантования в полной точности, что «съедало» 1–2 лишних бита на каждое значение и сводило на нет часть выгоды.
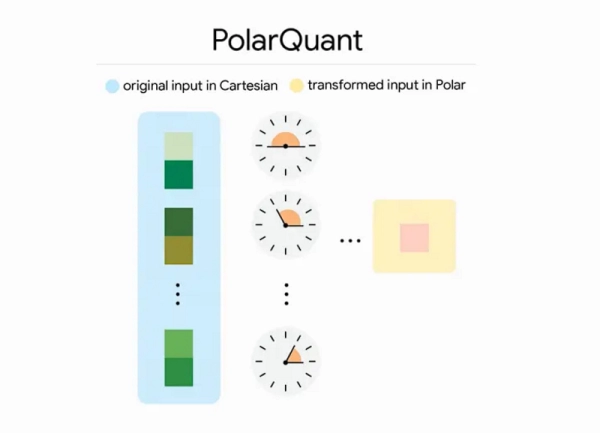 TurboQuant решает эту задачу принципиально новым двухэтапным подходом, основанным на теоретически обоснованной векторной квантизации.
TurboQuant решает эту задачу принципиально новым двухэтапным подходом, основанным на теоретически обоснованной векторной квантизации.
На первом этапе работает PolarQuant - метод, который переводит векторы из декартовых координат в полярные. Данные случайно поворачиваются, координаты группируются попарно, а углы концентрируются на фиксированной круговой сетке. Благодаря этому отпадает необходимость в нормализации каждого блока, и сжатие становится чрезвычайно эффективным без «словаря» overhead. На выходе получается компактное представление радиуса (величины вектора) и углов (направления).
Второй этап - Quantized Johnson-Lindenstrauss (QJL) - добавляет минимальную коррекцию ошибок. Остаточная погрешность после первого этапа проецируется в пространство меньшей размерности, а каждое значение сводится всего к одному знаковому биту (+1 или −1). Этот 1-битный «корректор» полностью убирает систематическую погрешность при вычислении оценок внимания, сохраняя математическую эквивалентность оригиналу.
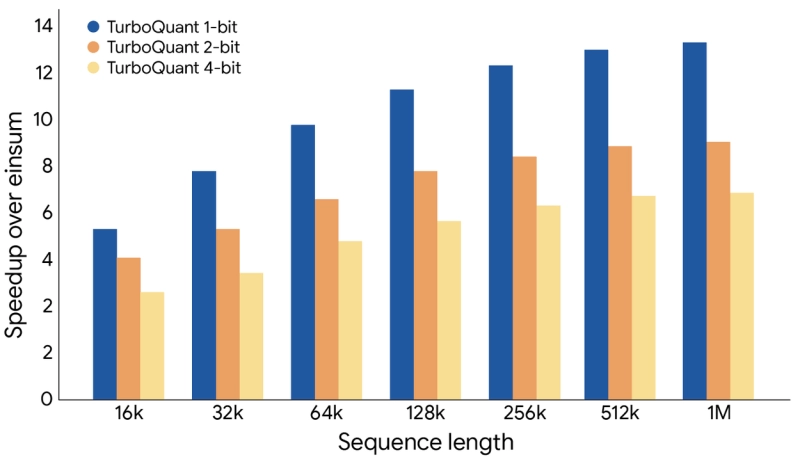
В итоге TurboQuant сжимает KV-cache до 3–3,5 бит на значение (в отдельных случаях - до 2,5 бит с учётом выбросов), то есть в шесть и более раз по сравнению со стандартными 16-битными представлениями.
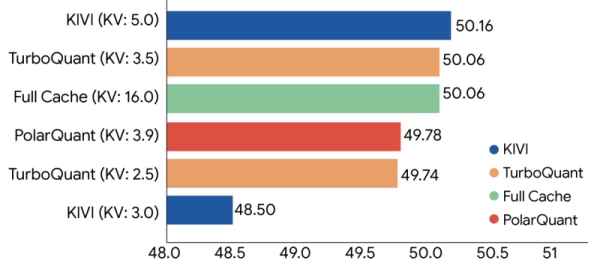
Результаты тестирования впечатляют. На открытых моделях Gemma и Mistral, а также в бенчмарках LongBench, Needle-in-a-Haystack, ZeroSCROLLS, RULER и L-Eval алгоритм показал полную нейтральность по качеству: ответы на вопросы, генерация кода и создание саммари ничем не отличаются от оригинала.
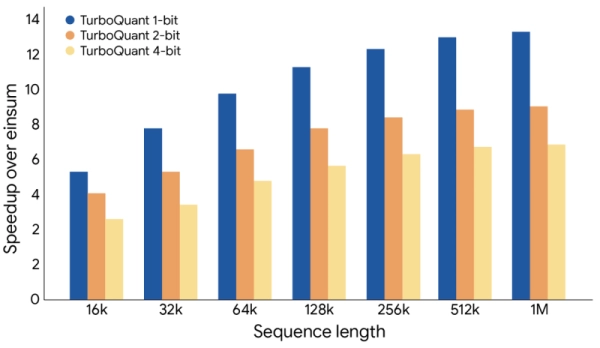
 В задаче «иголки в стоге сена» с длинным контекстом TurboQuant обеспечивает идеальный recall. На ускорителях NVIDIA H100 4-битная версия даёт до восьмикратное ускорение вычисления логитов внимания по сравнению с 32-битными ключами - при практически нулевых дополнительных затратах на runtime.
В задаче «иголки в стоге сена» с длинным контекстом TurboQuant обеспечивает идеальный recall. На ускорителях NVIDIA H100 4-битная версия даёт до восьмикратное ускорение вычисления логитов внимания по сравнению с 32-битными ключами - при практически нулевых дополнительных затратах на runtime.
Не менее важно, что TurboQuant одинаково эффективен и для векторного поиска. Он сокращает время индексации до практически нуля, превосходит классические методы вроде Product Quantization по точности recall на датасете GloVe и сохраняет геометрическую структуру векторов с минимальным искажением. Алгоритм полностью data-oblivious (не зависит от распределения данных) и работает в онлайн-режиме - его можно применять «на лету» без предварительного обучения или файн-тюнинга.
Для индустрии это означает не просто экономию. Снижение требований к памяти открывает дорогу к более длинным контекстам на тех же GPU, удешевляет inference (по некоторым оценкам - до 50 % и больше) и приближает момент, когда мощные модели смогут работать на устройствах с ограниченными ресурсами.
 В Google подчёркивают: это фундаментальный шаг к масштабируемому ИИ, где эффективность становится важнее грубой вычислительной мощи.
В Google подчёркивают: это фундаментальный шаг к масштабируемому ИИ, где эффективность становится важнее грубой вычислительной мощи.
TurboQuant уже готов к презентации на ведущих конференциях - основная работа выйдет на ICLR 2026, а вспомогательные PolarQuant и QJL - на AISTATS и AAAI. Пока это исследовательский прорыв, но его математическая строгость и практические результаты заставляют поверить, что очень скоро он найдёт место в реальных продуктах.
В эпоху, когда память остаётся одним из главных ограничителей ИИ, Google предложила решение, которое выглядит одновременно элегантным и революционным.
Ранее мы писали о том, что Обзор Samsung Galaxy A55: стильный середнячок с премиальным характером · Samsung Galaxy A55 5G - это смартфон среднего ценового сегмента, который пытается балансировать между доступной ценой и премиальными характеристиками. Он стал преемником популярного Galaxy A54, получив несколько... далее
Исследователи Google Research 24 марта 2026 года объявили о новом прорыве в области сжатия данных для искусственного интеллекта. Алгоритм TurboQuant, разработанный командой под руководством Амира Зандиха и Вахаба Миррокни, предлагает радикальное решение одной из самых острых проблем современных больших языковых моделей - огромного объёма рабочей памяти, необходимой для обработки длинных контекстов. Вместо того чтобы просто уменьшать модель,
TurboQuant фокусируется на ключевом узком месте - кэше ключей и значений (KV-cache) в механизмах внимания трансформеров, сжимая его минимум в шесть раз без какой-либо потери точности.
Проблема KV-cache хорошо знакома всем, кто работает с ИИ. Во время генерации текста модель сохраняет промежуточные результаты внимания, чтобы не пересчитывать их заново на каждом шаге. При росте окна контекста до сотен тысяч токенов этот кэш разрастается экспоненциально и быстро становится самым дорогим ресурсом - как по памяти, так и по скорости.
Традиционные методы квантизации (снижения разрядности) помогали, но вводили дополнительные накладные расходы: для каждого маленького блока данных приходилось хранить константы квантования в полной точности, что «съедало» 1–2 лишних бита на каждое значение и сводило на нет часть выгоды.
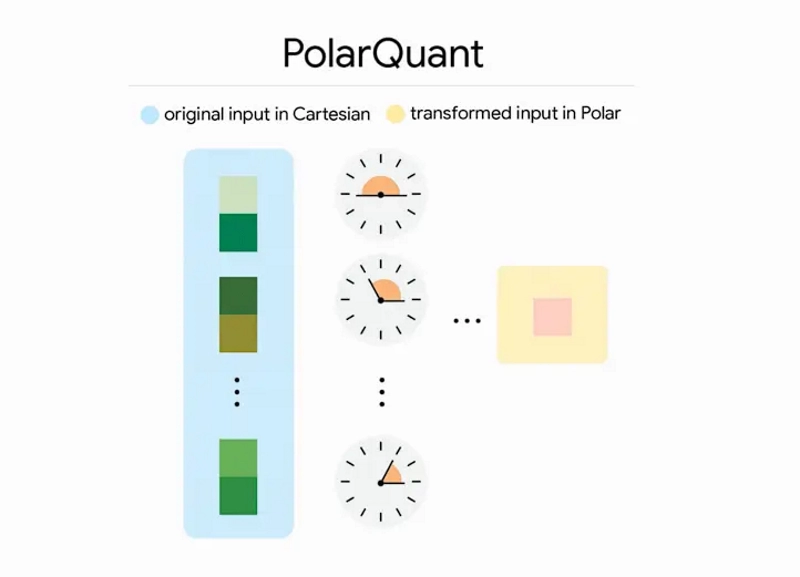 TurboQuant решает эту задачу принципиально новым двухэтапным подходом, основанным на теоретически обоснованной векторной квантизации.
TurboQuant решает эту задачу принципиально новым двухэтапным подходом, основанным на теоретически обоснованной векторной квантизации.
На первом этапе работает PolarQuant - метод, который переводит векторы из декартовых координат в полярные. Данные случайно поворачиваются, координаты группируются попарно, а углы концентрируются на фиксированной круговой сетке. Благодаря этому отпадает необходимость в нормализации каждого блока, и сжатие становится чрезвычайно эффективным без «словаря» overhead. На выходе получается компактное представление радиуса (величины вектора) и углов (направления).
Второй этап - Quantized Johnson-Lindenstrauss (QJL) - добавляет минимальную коррекцию ошибок. Остаточная погрешность после первого этапа проецируется в пространство меньшей размерности, а каждое значение сводится всего к одному знаковому биту (+1 или −1). Этот 1-битный «корректор» полностью убирает систематическую погрешность при вычислении оценок внимания, сохраняя математическую эквивалентность оригиналу.
Результаты тестирования впечатляют. На открытых моделях Gemma и Mistral, а также в бенчмарках LongBench, Needle-in-a-Haystack, ZeroSCROLLS, RULER и L-Eval алгоритм показал полную нейтральность по качеству: ответы на вопросы, генерация кода и создание саммари ничем не отличаются от оригинала.
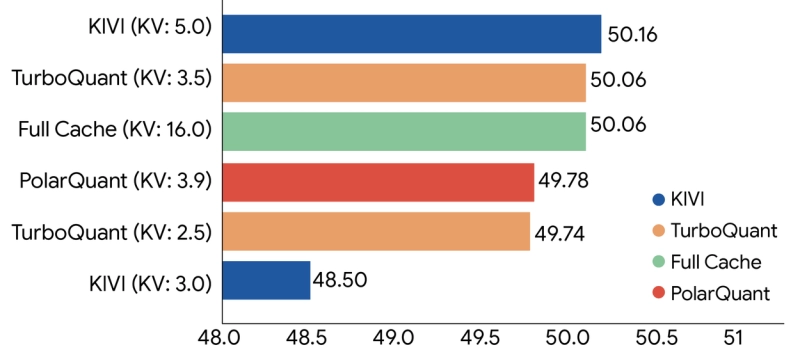 В задаче «иголки в стоге сена» с длинным контекстом TurboQuant обеспечивает идеальный recall. На ускорителях NVIDIA H100 4-битная версия даёт до восьмикратное ускорение вычисления логитов внимания по сравнению с 32-битными ключами - при практически нулевых дополнительных затратах на runtime.
В задаче «иголки в стоге сена» с длинным контекстом TurboQuant обеспечивает идеальный recall. На ускорителях NVIDIA H100 4-битная версия даёт до восьмикратное ускорение вычисления логитов внимания по сравнению с 32-битными ключами - при практически нулевых дополнительных затратах на runtime.
Не менее важно, что TurboQuant одинаково эффективен и для векторного поиска. Он сокращает время индексации до практически нуля, превосходит классические методы вроде Product Quantization по точности recall на датасете GloVe и сохраняет геометрическую структуру векторов с минимальным искажением. Алгоритм полностью data-oblivious (не зависит от распределения данных) и работает в онлайн-режиме - его можно применять «на лету» без предварительного обучения или файн-тюнинга.
Для индустрии это означает не просто экономию. Снижение требований к памяти открывает дорогу к более длинным контекстам на тех же GPU, удешевляет inference (по некоторым оценкам - до 50 % и больше) и приближает момент, когда мощные модели смогут работать на устройствах с ограниченными ресурсами.
 В Google подчёркивают: это фундаментальный шаг к масштабируемому ИИ, где эффективность становится важнее грубой вычислительной мощи.
В Google подчёркивают: это фундаментальный шаг к масштабируемому ИИ, где эффективность становится важнее грубой вычислительной мощи.
TurboQuant уже готов к презентации на ведущих конференциях - основная работа выйдет на ICLR 2026, а вспомогательные PolarQuant и QJL - на AISTATS и AAAI. Пока это исследовательский прорыв, но его математическая строгость и практические результаты заставляют поверить, что очень скоро он найдёт место в реальных продуктах.
В эпоху, когда память остаётся одним из главных ограничителей ИИ, Google предложила решение, которое выглядит одновременно элегантным и революционным.
Ранее мы писали о том, что Обзор Samsung Galaxy A55: стильный середнячок с премиальным характером · Samsung Galaxy A55 5G - это смартфон среднего ценового сегмента, который пытается балансировать между доступной ценой и премиальными характеристиками. Он стал преемником популярного Galaxy A54, получив несколько... далее